Chapter 2.5: Primary vs. Secondary Data Sources
This chapter examines the fundamental distinction between primary and secondary data sources in data science applications. The analysis covers strategic decision-making frameworks for data source selection, methodological approaches for different data collection strategies, and quality assessment criteria for evaluating data sources in organizational and research contexts.
Fundamental Distinctions in Data Source Categories
Primary data sources represent information collected directly by researchers or analysts for specific purposes, providing firsthand observations, measurements, or responses that address particular research questions. Secondary data sources encompass information originally collected by other individuals or organizations for different purposes but potentially valuable for new analytical objectives.
The distinguishing characteristic of primary data lies in its original nature—researchers directly control the entire data collection process, from initial design through final analysis. This control enables precise alignment between research objectives and data characteristics, but requires expertise in research design and substantial resource commitment. When the Johns Hopkins Center for Health Security conducted original surveys of healthcare workers during the COVID-19 pandemic, they made every methodological decision about question formulation, sample selection, and data collection timing.
Secondary data sources, conversely, involve leveraging pre-existing information systems designed for other purposes. This approach enables access to extensive datasets that would be prohibitively expensive or time-consuming to collect independently, though it requires careful evaluation of data quality, relevance, and appropriateness for specific research questions. The COVID-19 response demonstrated this approach when researchers accessed state health department databases, hospitalization records, and federal surveillance systems to track infection patterns and health outcomes.

Figure 2.5.1: Strategic framework illustrating the relationship between research objectives, resource constraints, and data source selection. The framework shows how different combinations of specificity, time pressure, and available resources lead to optimal data source choices between primary collection, secondary analysis, or hybrid approaches.
Primary Data Collection Methodologies and Applications
Primary data collection manifests through multiple methodological approaches across different analytical contexts. Survey research involves systematic collection of responses from selected populations using questionnaires administered through various channels. Healthcare organizations frequently conduct patient satisfaction surveys to understand service quality dimensions that administrative records cannot capture, generating original data about patient experiences, preferences, and perceptions that enable quality improvement initiatives tailored to specific organizational contexts.
Dr. Jennifer Nuzzo’s team at Johns Hopkins Center for Health Security exemplifies systematic primary data collection through their survey of over 12,000 healthcare workers across 50 states during the COVID-19 pandemic. The 47-question survey instrument was designed specifically to capture information about PPE shortages, workplace safety protocols, and mental health impacts that existing databases could not provide, achieving response rates exceeding 78% and generating insights essential for policy recommendations.
Experimental research represents another primary data approach where researchers manipulate variables under controlled conditions to establish causal relationships. Technology companies routinely conduct A/B tests to evaluate new website features, product designs, or marketing strategies, generating original data about user behavior under different conditions. This methodology enables evidence-based decisions about product development and marketing approaches while maintaining complete control over experimental variables and measurement procedures.
Observational studies involve systematic recording of naturally occurring phenomena without experimental manipulation. Retail organizations often conduct observational research to understand customer shopping patterns, recording behaviors like time spent in different store sections, product examination sequences, and purchase decision processes. This primary data provides insights into consumer behavior that transaction records alone cannot reveal, enabling organizations to optimize store layouts, product placement, and customer service strategies.
Primary Data Collection Characteristics:
Advantages: Precise alignment with research objectives; complete control over data quality and collection methods; ability to address novel questions not answered by existing sources; potential for competitive advantage through proprietary insights.
Limitations: High costs for design and implementation; substantial time requirements from planning through analysis; potential for researcher bias in design and execution; practical limitations on sample size and scope.
Secondary Data Source Categories and Accessibility
Government databases represent one of the most extensive and reliable categories of secondary data sources. Federal agencies like the Bureau of Labor Statistics, Census Bureau, and National Center for Health Statistics maintain comprehensive datasets covering employment, demographics, health outcomes, and economic indicators. These databases provide historical depth, large sample sizes, and standardized collection methods that enable robust statistical analysis across time periods and geographic regions.
The Bureau of Labor Statistics Employment Situation Summary provides monthly data on unemployment rates, job creation, and workforce participation that economists, policymakers, and business analysts use for forecasting and strategic planning. This information would be impossible for individual organizations to collect independently, but government investment in systematic data collection makes it freely available for secondary analysis with standardized collection methods and quality assurance procedures ensuring data reliability.
Commercial databases offer specialized information that private companies collect as part of their business operations or research activities. Financial services firms maintain extensive databases of market data, transaction patterns, and economic indicators that other organizations can access through licensing agreements. Nielsen and other market research companies provide consumer behavior data, brand awareness measurements, and advertising effectiveness metrics based on continuous data collection from representative consumer panels.
Academic and research institutions contribute significant secondary data resources through large-scale studies, longitudinal research projects, and survey initiatives. The General Social Survey, conducted by the National Opinion Research Center since 1972, provides decades of data about American attitudes, behaviors, and demographic characteristics. Researchers worldwide use this database to study social trends, political attitudes, and cultural changes over time, demonstrating the value of sustained data collection efforts for longitudinal analysis.
Open data initiatives have dramatically expanded secondary data availability in recent years. Government transparency efforts, philanthropic organization investments, and international development agencies now provide free access to datasets covering topics from climate monitoring to economic development indicators. The World Bank Open Data platform includes hundreds of indicators across countries and time periods, enabling comparative analysis of development trends, policy impacts, and economic relationships.
Strategic Evaluation Framework for Source Selection
Research question specificity often determines the most appropriate data source approach. Highly specific questions that require precise variable definitions or novel measurement approaches typically favor primary data collection. Organizations needing to understand customer reactions to specific new product features find that existing market research databases are unlikely to provide sufficiently detailed information about those particular features, necessitating primary data collection through surveys, focus groups, or user testing.
Conversely, research questions addressing broad patterns, trends, or comparative analysis often benefit from secondary data sources that provide extensive coverage across time periods, geographic regions, or population segments. Understanding general economic trends, demographic changes, or industry-wide patterns typically requires large-scale data that individual organizations cannot feasibly collect independently.
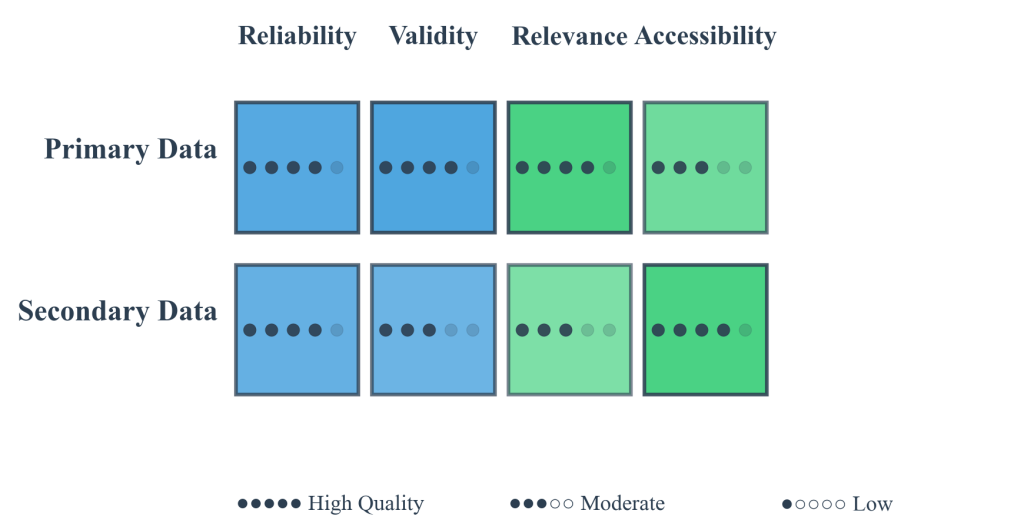
Figure 2.5.2: Comprehensive quality assessment matrix showing evaluation criteria for both primary and secondary data sources. The matrix displays the relationship between different quality dimensions (reliability, validity, relevance, accessibility) and their application to different data source types, providing a systematic framework for data source evaluation.
Resource and Time Considerations: Primary data collection requires substantial investments in research design, data collection infrastructure, participant recruitment, and analysis capabilities. Organizations with limited budgets or compressed timelines may find secondary data sources more feasible, particularly when existing databases provide adequate coverage of relevant variables and populations. Time sensitivity represents another crucial consideration, as secondary data sources typically provide immediate access to information, enabling rapid analysis and decision-making when timing is critical.
Quality Assessment and Methodological Validation
Data quality assessment involves multiple dimensions that apply differently to primary and secondary sources. For primary data, quality control occurs through research design decisions about sampling methods, measurement instruments, data collection procedures, and quality assurance protocols. Quality evaluation focuses on ensuring that methodological choices align with research objectives and produce reliable, valid measurements of relevant constructs.
Secondary data quality assessment requires different evaluation approaches since analysts cannot control original collection methods. Evaluation must determine whether the original data collection procedures meet quality standards and research needs, including examination of documentation about sampling methods, response rates, measurement validity, and any known limitations or biases in the original data collection process.
Relevance evaluation determines whether available data sources address specific research questions adequately. Primary data collection enables perfect alignment between research objectives and data characteristics, since researchers design the data collection process specifically for their purposes. However, this alignment requires expertise in research design and careful attention to measurement validity and reliability.
Secondary data relevance depends on the match between original collection purposes and analytical objectives. Government employment statistics may provide excellent data for understanding broad labor market trends but insufficient detail for analyzing specific industry subsectors or occupational categories relevant to particular research questions.
Integration Strategies and Hybrid Approaches
Hybrid approaches often provide optimal solutions by combining primary and secondary data sources strategically. Organizations might use secondary data for baseline analysis and trend identification, then conduct targeted primary data collection to address specific questions not answered by existing sources. This approach maximizes analytical comprehensiveness while managing resource investments efficiently.
The Johns Hopkins COVID-19 response team strategically combined primary surveys revealing healthcare worker experiences with secondary databases providing infection trends and hospitalization capacity. Primary surveys revealed that 87% of frontline workers reported PPE shortages compared to 34% in federal agency databases, providing essential context for interpreting secondary statistics and demonstrating the value of integrated data source approaches for comprehensive understanding.
Retail organizations exemplify effective integration strategies by analyzing secondary market research data to understand general consumer trends and competitive positioning, then conducting primary survey research to understand customer reactions to specific product concepts or brand messaging strategies. The combination provides both broad market context and specific actionable insights while optimizing resource allocation across different analytical objectives.
Accessibility evaluation determines whether necessary data can be obtained within resource and time constraints. Primary data collection provides complete access to all collected information but requires substantial investment in collection infrastructure and expertise. Secondary data access varies dramatically from free government databases to expensive commercial services, with different usage restrictions and licensing requirements that may affect project feasibility and timeline planning.
Systematic Integration Framework:
1. Baseline Analysis: Use secondary data to establish context and identify knowledge gaps
2. Gap Assessment: Determine which questions cannot be answered with available secondary sources
3. Targeted Collection: Design primary data collection to address specific gaps
4. Validation: Use primary data to validate or contextualize secondary data findings
5. Synthesis: Integrate findings across data sources for comprehensive analysis
This systematic evaluation process enables informed decisions about data source selection and appropriate interpretation of analytical results, ensuring that chosen approaches support valid conclusions and effective decision-making within resource and time constraints while maximizing the value of available information sources.
References
Adhikari, A., DeNero, J., & Wagner, D. (2022). Computational and inferential thinking: The foundations of data science (2nd ed.). https://inferentialthinking.com/
Centers for Disease Control and Prevention. (2024). COVID-19 response and surveillance. https://www.cdc.gov/coronavirus/2019-ncov/index.html
Dong, E., Du, H., & Gardner, L. (2020). An interactive web-based dashboard to track COVID-19 in real time. The Lancet Infectious Diseases, 20(5), 533-534. https://doi.org/10.1016/S1473-3099(20)30120-1
Irizarry, R. A. (2024). Introduction to data science: Data wrangling and visualization with R. https://rafalab.dfci.harvard.edu/dsbook-part-1/
Johns Hopkins Center for Health Security. (2024). COVID-19 testing, contact tracing, and case investigation. https://www.centerforhealthsecurity.org/
National Opinion Research Center. (2024). General Social Survey. https://gss.norc.org/
Timbers, T., Campbell, T., & Lee, M. (2024). Data science: A first introduction. https://datasciencebook.ca/
U.S. Bureau of Labor Statistics. (2024). Employment situation summary. https://www.bls.gov/news.release/empsit.nr0.htm
World Bank. (2024). World Bank open data. https://data.worldbank.org/
