Chapter 3.2: Recognizing Data Quality Issues and Their Impact
This chapter examines the systematic identification and categorization of data quality problems that compromise analytical reliability and business operations. Key concepts include missing value patterns, duplicate record detection, formatting inconsistencies, and data type mismatches. The analysis establishes the foundation for professional data preparation techniques that transform unreliable raw data into trustworthy analytical assets.
The Economic Magnitude of Data Quality Problems
Data quality issues represent a systematic challenge facing modern organizations, with research by Thomas C. Redman demonstrating that poor data quality costs organizations an average of $3.1 trillion annually in the United States alone (Redman, 2016). Customer service operations experience disproportionate impact, with representatives requiring 30-40% additional time per interaction when working with inconsistent data. Automated communication systems demonstrate delivery failure rates of 25-35% when customer contact information contains formatting errors or duplicates.
The complexity extends beyond operational inefficiencies to compliance and analytical integrity. Organizations in regulated industries face potential penalties when demographic data gaps prevent accurate reporting, while duplicate customer records trigger audit findings and regulatory scrutiny. These systematic patterns of data degradation follow predictable forms that enable proactive identification and remediation.
The Four Primary Categories of Data Quality Issues
Missing Information Patterns
Missing values manifest in every real-world dataset, yet their analytical impact varies dramatically based on underlying patterns and business context. Random missing data reduces statistical power but typically maintains analytical validity through appropriate handling techniques. Systematic missing data creates fundamental analytical problems when specific subgroups consistently omit information—such as high-income customers avoiding demographic questions or certain product categories lacking pricing data.
Pattern Recognition: Systematic missing data often correlates with sensitive information requests, technical system limitations, or business process gaps. Organizations observe consistent patterns where voluntary demographic data shows higher missing rates among specific populations, while mandatory operational data exhibits missing patterns tied to system integration failures.
The analytical consequences compound when missing data correlates with outcomes of interest. When customer satisfaction surveys exhibit higher non-response rates among dissatisfied customers, the resulting analysis systematically understates service problems. When product performance data lacks information for failing items, quality assessments become fundamentally biased toward successful products.
Duplicate Record Multiplication
Duplicate records create analytical distortions that inflate counts, skew statistical measures, and generate compliance violations in regulated industries. Customer databases commonly contain multiple representations of identical individuals through name variations, address changes, or separate account creation processes. The multiplication effect extends beyond simple counting errors to create false demographic patterns and inflated customer lifetime value calculations.
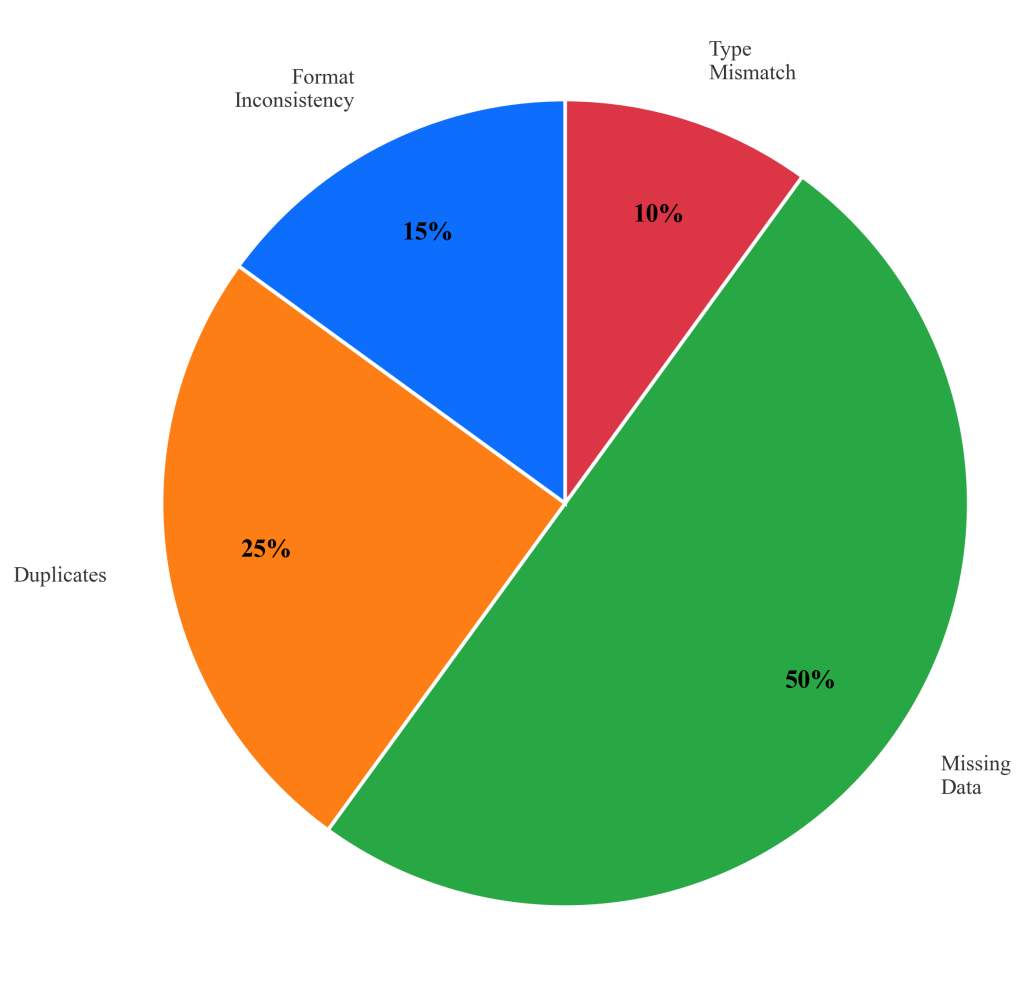
Figure 3.2.1: Distribution of common data quality issues in organizational databases. Missing data represents the most frequent category, while the combination of multiple issue types creates compounding analytical problems that require systematic identification and remediation approaches.
Professional identification requires understanding the business processes that generate duplicates. Online retail platforms observe duplicate customer accounts when users create multiple profiles with slight name variations. Enterprise systems generate duplicates during data migration projects when matching algorithms fail to recognize identical entities with formatting differences. Healthcare systems create safety risks when patient information appears multiple times with inconsistent medical history linkages.
Formatting Inconsistency Problems
Formatting inconsistencies transform straightforward analytical tasks into complex data manipulation challenges, preventing automated processing and creating systematic analytical errors. Phone numbers entered with varying punctuation schemes—parentheses, dashes, spaces, or plain digits—prevent automated dialing systems from functioning properly. Date information in multiple formats confuses time-series analysis and prevents chronological sorting accuracy.
Excel Detection Methodology: Conditional formatting reveals inconsistent patterns through visual highlighting. The TRIM function removes extra spaces that create false formatting differences. Text-to-columns functionality splits improperly concatenated fields. CONCATENATE and standardized formatting functions enable systematic correction of identified inconsistencies across large datasets.
Currency values mixed with text descriptions make financial calculations impossible without extensive preprocessing. Address information with inconsistent abbreviation standards prevents automated geocoding and delivery optimization. These formatting problems multiply exponentially when organizations merge data from multiple sources with different entry standards.
Data Type Classification Errors
Data type mismatches occur when numerical information becomes stored as text, preventing mathematical operations and statistical analysis. This systematic problem emerges when leading zeros require preservation, when numbers include currency symbols or measurement units, or when data importation processes default to text formatting for safety. The identification requires systematic verification of data types before analytical procedures begin.
Recognition Indicators: Excel displays text-formatted numbers with left alignment rather than right alignment. The VALUE function reveals whether apparent numbers can convert to numeric format. SUM functions return zero when attempting to calculate with text-formatted numeric data, providing immediate diagnostic feedback.
Industry-Specific Impact Manifestations
Retail Customer Management
Online retail organizations encounter data quality challenges that directly impact customer experience and operational efficiency. Duplicate customer accounts prevent consolidated purchase history analysis, leading to inappropriate marketing communications and loyalty program confusion. Missing email addresses eliminate automated order confirmation capabilities, requiring expensive manual customer service interventions. Inconsistent address formatting causes shipping delays, increased return rates, and customer satisfaction problems.
Healthcare Information Systems
Medical facilities face severe safety and compliance consequences from data quality problems. Patient record duplicates can prevent critical medical history from appearing during emergency treatments, creating life-threatening situations. Missing allergy information compromises medication safety protocols. Inconsistent name formatting across interconnected systems prevents comprehensive care coordination between specialists and primary care providers.
Financial Services Risk Assessment
Banking institutions encounter regulatory compliance violations when customer demographic data contains systematic gaps or duplicates. Inconsistent income formatting prevents accurate loan risk calculations, potentially leading to inappropriate lending decisions. Missing employment information compromises know-your-customer requirements and anti-money laundering compliance protocols.
Professional Practice: Financial institutions employ systematic data quality monitoring using automated validation rules, regular duplicate detection procedures, and standardized formatting requirements. These systematic approaches typically reduce data quality issues by 85-95% while improving operational efficiency and regulatory compliance posture.
Systematic Quality Assessment Approach
Professional data quality management follows systematic approaches rather than ad-hoc correction strategies. Organizations implement standardized data entry procedures, utilize validation rules to prevent inconsistencies at input, and establish regular cleaning protocols using analytical tools. The systematic approach begins with comprehensive quality assessment that identifies patterns rather than individual errors.
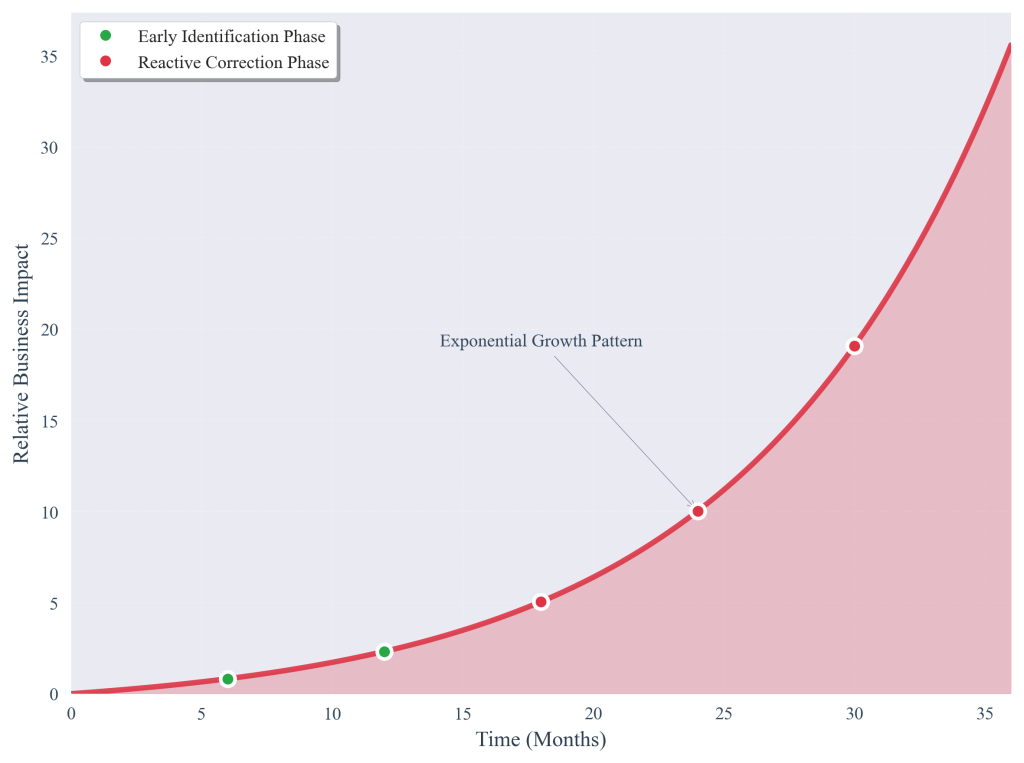
Figure 3.2.2: Timeline showing cumulative business impact of unaddressed data quality issues. The exponential growth pattern demonstrates why early identification and systematic remediation prove more cost-effective than reactive correction approaches after analytical errors emerge.
The assessment methodology requires both technical detection capabilities and business context understanding. Technical detection identifies formatting inconsistencies, missing value patterns, and potential duplicates through systematic scanning procedures. Business context evaluation determines which quality issues create the most significant operational or analytical impact, enabling prioritized remediation efforts.
Excel Quality Assessment Workflow: Conditional formatting reveals missing data patterns instantly. Data validation prevents inconsistent entries before occurrence. The Remove Duplicates feature provides initial duplicate detection, though professional cleaning requires understanding underlying causes. Find and Replace operations standardize inconsistent values across large datasets when applied systematically.
Prevention and Professional Development
Developing systematic data quality assessment capabilities transforms analytical professionals from reactive problem-solvers into proactive quality managers. This methodological shift proves valuable across career paths, as every organization depends on reliable data for operational and strategic decision-making. Pattern recognition skills enable rapid quality assessment that anticipates common problems before they compromise analytical integrity.
Professional development emphasizes understanding why quality issues occur rather than simply fixing individual problems. Customer data formatting inconsistencies often result from multiple entry points with different validation standards. Survey missing data patterns typically correlate with question sensitivity or survey length. Duplicate records frequently emerge from business process gaps during customer onboarding or system migration activities.
Ethical Considerations: Data quality assessment must balance thoroughness with privacy protection. Systematic duplicate detection should avoid unnecessarily linking separate customer identities. Missing data analysis should consider whether data gaps reflect deliberate privacy choices rather than system failures. Quality improvement should enhance rather than compromise individual privacy protections.
Integration with Advanced Analytical Techniques
Systematic data quality recognition forms the foundation for advanced analytical methodologies explored in subsequent chapters. Statistical analysis requires understanding missing data patterns to select appropriate handling techniques. Data visualization depends on consistent formatting to enable automated chart generation. Machine learning applications demand comprehensive quality assessment to prevent biased model training from systematically flawed input data.
The recognition skills developed through systematic quality assessment enable confident progression to specialized cleaning techniques, validation procedures, and documentation standards that characterize professional data science practice. Organizations implementing systematic quality management observe substantial improvements in analytical reliability, operational efficiency, and regulatory compliance outcomes.
This systematic approach to data quality recognition enables reliable analytical foundations that support evidence-based decision-making across organizational contexts and analytical applications.
