Chapter 4.6: Measures of Variability
This chapter examines measures of variability that quantify data dispersion patterns, enabling comprehensive assessment of consistency, reliability, and predictability in business datasets. Key concepts include range calculations, standard deviation analysis, variance interpretation, and coefficient of variation applications for comparative analysis across different scales and contexts.
Understanding Variability in Business Analytics
Measures of variability quantify the degree to which individual observations in a dataset differ from central tendency measures, providing essential insights into data consistency, reliability, and predictability. While central tendency measures identify typical or representative values, variability measures reveal the extent of dispersion around those central points, enabling comprehensive characterization of distribution patterns and underlying process stability.
The significance of variability assessment extends across all domains of business analytics, from quality control applications that monitor manufacturing consistency to financial risk analysis that evaluates investment volatility patterns. Understanding dispersion characteristics enables evidence-based decision-making that accounts for both typical performance levels and the range of variation around those averages, supporting more robust strategic planning and operational management.
Professional Application Context: PrecisionTech Industries exemplifies systematic variability analysis applications in manufacturing quality control. The company’s six production facilities produced components with average dimensions meeting specifications (24.97mm against target 25.00mm ± 0.05mm), yet customer complaints indicated underlying quality issues invisible in central tendency reporting. Comprehensive variability analysis revealed Production Line A achieving standard deviation σ = 0.012mm compared to Line C’s σ = 0.031mm, indicating dramatically different manufacturing precision levels despite similar averages. This dispersion analysis enabled targeted process improvements that reduced warranty costs by $2.3 million annually.
Range as Fundamental Variability Assessment
Range represents the simplest measure of variability, calculated as the difference between maximum and minimum values in a dataset. This straightforward measure provides immediate insight into data spread and enables rapid assessment of variation magnitude without complex mathematical operations. Range calculations offer intuitive interpretation because they express variability in the same units as original data, making results immediately accessible to non-technical audiences in business contexts.
Business applications of range analysis include quality control monitoring, performance evaluation, and risk assessment where understanding extreme variations provides critical operational insights. Manufacturing processes with small ranges indicate consistent output quality, while service delivery times with large ranges suggest operational inconsistencies requiring management attention. The computational simplicity of range calculations enables real-time monitoring applications where immediate feedback supports operational decision-making.
Excel Implementation Methodology: Range calculations utilize Excel’s MAX() and MIN() functions through the formula =MAX(range)-MIN(range), providing immediate variability assessment. Advanced applications combine range analysis with conditional functions to identify outlier-influenced ranges versus typical operational ranges. JASP software provides automatic range reporting within descriptive statistics output, facilitating integration with comprehensive analytical workflows.
Figure 4.6.1: Visual comparison of range and standard deviation measures demonstrating how range captures extreme variations while standard deviation provides comprehensive dispersion assessment. The diagram illustrates manufacturing quality control applications where both measures inform process consistency evaluation.
However, range measurements prove sensitive to outliers that might misrepresent overall data variability patterns. A single extreme observation can dramatically inflate range values while the majority of data remains tightly clustered, creating misleading impressions of process consistency or performance reliability. Professional analysis combines range assessment with other variability measures that provide more comprehensive understanding of dispersion patterns resistant to outlier influence.
Standard Deviation and Variance Analysis
Standard deviation represents the most important and widely used variability measure in business analytics, quantifying the average distance between individual observations and the dataset mean. This measure provides intuitive interpretation because it expresses variability in the same units as original data, enabling direct comparison with central tendency measures and practical business benchmarks. Standard deviation calculations incorporate all data points rather than only extreme values, providing more stable and representative measures of dispersion.
The mathematical foundation of standard deviation enables advanced statistical applications including confidence interval construction, hypothesis testing procedures, and process control implementations. Unlike range calculations that consider only extreme observations, standard deviation reflects the contribution of every data point to overall variability assessment, providing more comprehensive characterization of distribution patterns and underlying process stability.
Statistical Distinction: Sample standard deviation calculations (using n-1 degrees of freedom) apply when analyzing subsets of larger populations, characterizing most business applications where complete population data remains unavailable. Population standard deviation calculations (using n degrees of freedom) apply when analyzing complete operational populations such as all employees, products, or transactions within defined periods. This distinction affects numerical results and influences subsequent statistical inference procedures.
Variance, calculated as the square of standard deviation, provides the mathematical foundation for advanced statistical procedures but proves less intuitive for business interpretation because it expresses variability in squared units. Variance calculations support advanced analytical procedures including analysis of variance (ANOVA) and regression analysis, but standard deviation remains preferable for operational decision-making contexts due to its direct interpretability and practical relevance in business communication.
Excel Implementation Methodology: Standard deviation calculations utilize Excel’s STDEV.S() function for sample data and STDEV.P() for population data, ensuring appropriate statistical inference. Variance calculations employ corresponding VAR.S() and VAR.P() functions. JASP provides both measures alongside interpretive guidance that supports business decision-making applications, including graphical representations of distribution characteristics and variability patterns.
Coefficient of Variation for Comparative Analysis
The coefficient of variation expresses standard deviation as a percentage of the mean, creating a standardized measure that enables comparison across different scales, units, and business contexts. This relative measure proves particularly valuable when comparing variability between different business units, product lines, or performance metrics with different measurement scales or magnitude levels, supporting strategic analysis and resource allocation decisions.
Coefficient of variation interpretation follows general guidelines where values below 15% indicate low variability suggesting consistent processes, 15-25% represents moderate variability requiring monitoring, and values exceeding 25% indicate high variability demanding management intervention. These thresholds vary by industry and operational context but provide useful benchmarks for initial variability assessment and comparative analysis across different business environments.
Multi-Unit Performance Analysis: Regional sales analysis demonstrates coefficient of variation applications in comparative business analysis. East Coast offices averaged $2.4 million monthly sales with σ = $480,000 (coefficient of variation = 20%), while West Coast offices averaged $850,000 with σ = $127,500 (coefficient of variation = 15%). Despite higher absolute variability, East Coast operations demonstrated proportionally less relative variability, indicating superior consistency relative to performance scale.
Business Applications and Decision-Making Context
Quality Control and Process Management
Manufacturing applications emphasize variability assessment for process control and quality assurance, recognizing that consistency matters as much as accuracy for customer satisfaction and regulatory compliance. Statistical process control utilizes variability measures to distinguish normal process variation from special cause variation requiring corrective intervention, enabling proactive quality management rather than reactive problem-solving approaches.
Service industries apply variability analysis to assess delivery time consistency, response quality uniformity, and customer experience reliability. Low variability in service delivery builds customer trust and competitive advantage, while high variability indicates operational inconsistencies requiring systematic improvement initiatives through training, process standardization, or resource allocation adjustments.
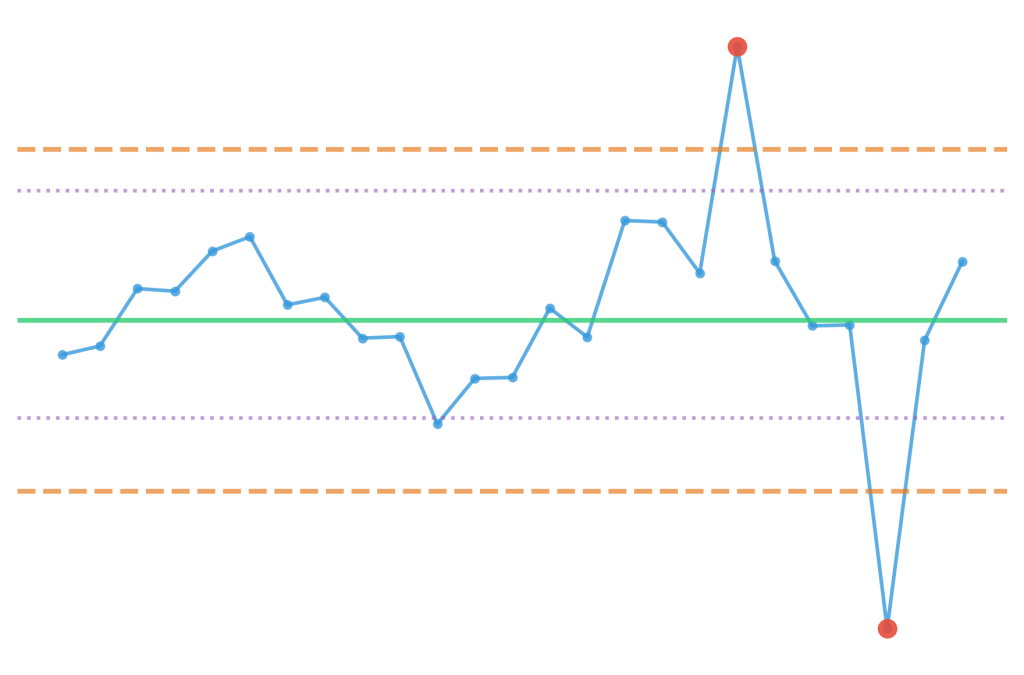
Figure 4.6.2: Statistical process control chart illustrating how variability measures establish control limits for quality management. The visualization demonstrates normal process variation versus special cause variation patterns that trigger management intervention, supporting proactive quality assurance in manufacturing environments.
Financial and Risk Management
Investment analysis utilizes standard deviation as the primary measure of volatility, quantifying investment risk for portfolio optimization and strategic asset allocation decisions. Modern portfolio theory relies on variability measures to balance expected returns against risk exposure, enabling systematic approaches to investment diversification that maximize returns while controlling downside risk through mathematical optimization procedures.
Operational risk assessment applies variability analysis to cash flow forecasting, demand planning, and resource allocation decisions. Understanding revenue variability enables appropriate reserve planning and contingency resource preparation, while expense variability assessment supports budgeting accuracy and financial control effectiveness in uncertain business environments.
Performance Management and Human Resources
Human resources applications use variability measures to assess team consistency, identify training needs, and develop equitable evaluation systems that account for performance range expectations. Teams with low performance variability indicate effective standardization and training programs, while high variability suggests skill gaps or process inconsistencies requiring targeted intervention through professional development initiatives.
Individual performance assessment considers variability patterns relative to team averages for fair goal setting and development planning that acknowledges realistic performance expectations. Understanding performance ranges enables appropriate expectation setting while encouraging continuous improvement through systematic skill development and process refinement based on measurable consistency improvements.
Ethical Considerations: Performance variability analysis requires careful consideration of factors beyond individual control, including resource availability, training quality, and systemic organizational challenges. Fair evaluation systems account for environmental factors that influence performance consistency while maintaining accountability for achievable improvement targets based on organizational support and individual capability development.
Advanced Variability Applications
Computational Considerations
Modern statistical software provides automated variability calculations that ensure computational accuracy while enabling focus on interpretation and application rather than manual calculation procedures. Spreadsheet applications offer built-in functions for all major variability measures, while specialized statistical packages provide additional diagnostic capabilities including distribution testing, outlier detection, and robust variability alternatives.
Large dataset analysis requires consideration of computational efficiency and memory requirements, particularly when analyzing millions of observations or conducting repeated calculations across multiple variables. Cloud-based analytical platforms provide scalable computing resources that enable variability analysis of enterprise-scale datasets without local hardware limitations or processing time constraints.
Limitations and Alternative Approaches
Variability measures assume numerical data with meaningful arithmetic operations, limiting their application to categorical or ordinal data types that require alternative analytical approaches. Distribution characteristics affect variability measure interpretation, with highly skewed data requiring careful consideration of appropriate measures and potential transformation procedures that normalize distribution patterns.
Outlier sensitivity varies among different variability measures, with range proving most sensitive and standard deviation showing moderate sensitivity to extreme observations. Robust variability measures such as interquartile range provide alternatives when outlier influence creates misleading impressions of typical dispersion patterns, supporting more accurate characterization of central distribution tendencies.
International Business Considerations: Cultural and contextual factors influence acceptable variability levels, with different industries and international markets accepting varying degrees of consistency based on operational constraints, customer expectations, and competitive requirements. Global operations require consideration of different quality standards and customer preferences that affect appropriate variability targets and improvement priorities across diverse market environments.
Integration with Statistical Analysis
Variability measures provide essential components for advanced statistical procedures including confidence interval construction, hypothesis testing, and regression analysis applications. Understanding dispersion characteristics enables appropriate method selection and result interpretation that accounts for data quality and distributional assumptions underlying statistical inference procedures.
The relationship between variability measures and distribution shapes informs analytical approach selection, with normal distributions supporting parametric statistical methods while non-normal patterns requiring robust alternatives or data transformation procedures. Professional statistical analysis integrates variability assessment with distribution characterization for comprehensive analytical frameworks that ensure appropriate method application and reliable result interpretation.
Integration Methodology: Comprehensive analytical workflows combine variability measures with distribution assessment, outlier detection, and normality testing to establish appropriate analytical foundations. Excel’s Data Analysis ToolPak provides integrated descriptive statistics that combine central tendency and variability measures with distribution characteristics, while JASP offers advanced diagnostic capabilities including distribution plots and statistical tests that inform subsequent analytical procedures.
This examination of variability measures establishes essential foundations for understanding data dispersion patterns that inform quality control, risk assessment, and performance management decisions across diverse business contexts. The systematic approach to variability analysis enables evidence-based decision-making that accounts for both central tendencies and dispersion characteristics, supporting more robust strategic planning and operational management in uncertain business environments.
Key References: Timbers, T., Campbell, T., & Lee, M. (2024). Data Science: A First Introduction. University of British Columbia. Irizarry, R. A. (2024). Introduction to Data Science: Data Wrangling and Visualization with R. Harvard University. Adhikari, A., DeNero, J., & Wagner, D. (2022). Computational and Inferential Thinking: The Foundations of Data Science (2nd ed.). University of California Press.
