Chapter 2.7: Data Ethics, Privacy, and Bias Considerations
This chapter examines fundamental ethical principles that guide responsible data collection and use in modern data science practice. Key concepts include privacy considerations and protection strategies that respect individual rights while enabling valuable analysis, recognition of different types of bias that can emerge in data collection processes, and regulatory frameworks that govern data use across different industries and contexts.
Case Study: Amazon’s Facial Recognition Technology and Algorithmic Bias
Amazon Web Services’ Rekognition facial recognition system represents a compelling example of how ethical considerations in data collection and use can evolve from theoretical concerns into real-world controversies with significant societal implications. Launched in 2016, Rekognition promised to revolutionize everything from retail security to law enforcement by automatically identifying faces in images and videos with unprecedented accuracy and scale. However, the technology’s rapid deployment revealed fundamental ethical challenges that illustrate why understanding bias, privacy, and fairness is essential for any data science professional.
The foundation of Rekognition’s capabilities rests on massive datasets of facial images used to train machine learning algorithms. These training datasets, like most data science resources, reflected the demographics and perspectives of their creators and sources. Early versions of the system demonstrated significantly higher error rates when analyzing faces of women and individuals with darker skin tones compared to white men. Dr. Joy Buolamwini’s research at MIT revealed that commercial facial recognition systems, including Amazon’s, showed error rates of up to 34.7% for dark-skinned women versus only 0.8% for light-skinned men when attempting to identify gender.
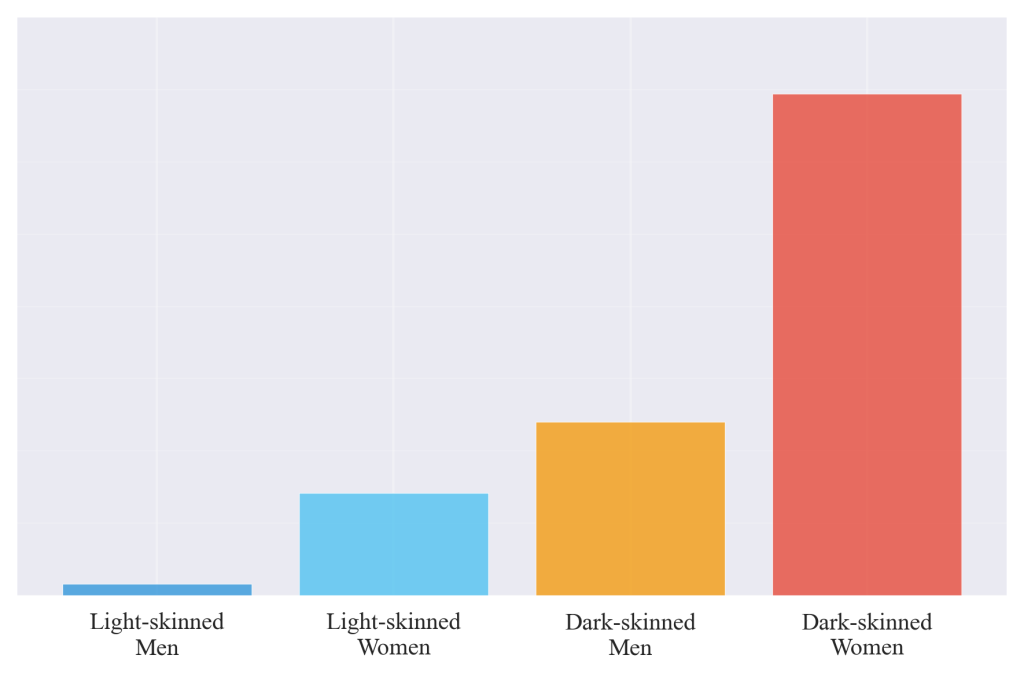
Figure 2.7.1: Comparative error rates in facial recognition systems across demographic groups demonstrate how training data composition affects algorithmic performance. The visualization illustrates how systematic underrepresentation in training datasets translates to disparate impacts on different communities, with darker-skinned women experiencing significantly higher error rates than light-skinned men.
This performance disparity emerged not from intentional discrimination, but from systematic biases in data collection processes that seemed neutral on the surface. Training datasets predominantly featured lighter-skinned individuals, particularly white men, because these populations were more heavily represented in the publicly available image databases that technology companies used for algorithm development. Professional photography, celebrity images, and social media photos—common sources for facial recognition training data—historically overrepresented certain demographic groups while underrepresenting others.
The privacy implications proved equally concerning as organizations began deploying Rekognition for surveillance applications. The American Civil Liberties Union discovered that Amazon had been actively marketing the technology to law enforcement agencies, enabling real-time identification of individuals in public spaces without their knowledge or consent. Unlike controlled applications such as smartphone unlocking, where individuals voluntarily participate in facial recognition, these surveillance implementations collected and analyzed personal biometric data from anyone who appeared in public camera feeds.
Foundational Ethical Principles in Data Science
The ethical foundations of data science rest on principles developed across multiple disciplines, including biomedical research, social sciences, and technology ethics. These principles provide a framework for evaluating the moral implications of data collection, analysis, and application decisions throughout the data science lifecycle. Understanding these foundations enables data science professionals to recognize ethical challenges early in projects and develop appropriate responses that protect individual rights while enabling beneficial applications.
Respect for Persons and Autonomy
The principle of respect for persons recognizes that individuals have the right to make informed decisions about how their personal information is collected, used, and shared. This principle, derived from biomedical research ethics, emphasizes that people should be treated as autonomous agents capable of directing their own lives rather than merely as sources of data for analytical purposes.
In data science practice, respect for persons manifests through informed consent processes that clearly explain what data is being collected, how it will be analyzed, and what the potential consequences might be for individuals and communities. True informed consent requires that people understand not just the immediate data collection, but also the potential for secondary uses, data sharing with third parties, and long-term storage implications that might not be apparent at the time of initial collection.
Beneficence and Non-Maleficence
These paired principles require that data science applications maximize benefits while minimizing potential harms to individuals and society. Beneficence demands that data collection and analysis serve purposes that improve human welfare, while non-maleficence insists on avoiding actions that could cause unnecessary harm or suffering.
Applying these principles requires careful consideration of both intended and unintended consequences of data science projects. While a predictive policing algorithm might reduce crime rates in some neighborhoods (beneficence), it could simultaneously increase surveillance and enforcement in communities that are already subject to disproportionate law enforcement attention (maleficence). Ethical data science practice requires systematically evaluating these trade-offs and implementing safeguards to minimize harmful outcomes.
Justice and Fairness
The principle of justice demands that the benefits and burdens of data science applications be distributed fairly across all segments of society, with particular attention to protecting vulnerable populations and avoiding the perpetuation of historical inequalities. This principle recognizes that data science has the power to either reinforce existing social disparities or help create more equitable outcomes.
Privacy Rights and Data Protection
Privacy in the digital age encompasses both the traditional notion of keeping personal information confidential and newer concepts related to individual control over personal data flows in complex technological systems. Understanding privacy requires recognizing that personal information can be sensitive not just because of its content, but because of how it can be combined, analyzed, and used to make inferences about individuals and their communities.
Types of Personal Information and Sensitivity
Personal data exists on a spectrum of sensitivity, with different types of information carrying different levels of risk and requiring different protection strategies:
Directly Identifying Information: Names, Social Security numbers, email addresses that clearly enable linking data back to specific individuals
Quasi-identifiers: Information that, while not directly identifying, can uniquely identify individuals when combined with other readily available data
Sensitive Attributes: Information that could lead to discrimination, stigmatization, or harm if disclosed inappropriately
Inferred Information: Conclusions drawn from data analysis rather than directly collected information
Research Finding: The combination of ZIP code, gender, and date of birth uniquely identifies 87% of the U.S. population according to research by Latanya Sweeney. This finding revolutionized thinking about data privacy by demonstrating that traditional anonymization techniques—simply removing names and obvious identifiers—provide insufficient protection in an era of big data and powerful analytical tools.
Privacy-Preserving Techniques and Strategies
Modern data science has developed numerous technical approaches for protecting privacy while enabling valuable analysis:
Differential Privacy: Adds carefully calibrated random noise to analytical results, ensuring that the inclusion or exclusion of any single individual’s data cannot be detected
K-anonymity: Ensures that any combination of quasi-identifying attributes appears for at least k individuals
Homomorphic Encryption: Enables computation on encrypted data without requiring decryption
Federated Learning: Allows machine learning models to be trained across distributed datasets without centralizing the underlying data
Understanding and Mitigating Bias in Data Collection and Analysis
Bias in data science emerges from multiple sources throughout the analytical pipeline, from initial data collection decisions through final application of analytical results. Understanding these different sources of bias is essential for developing systematic approaches to detection and mitigation that protect both analytical validity and social equity.
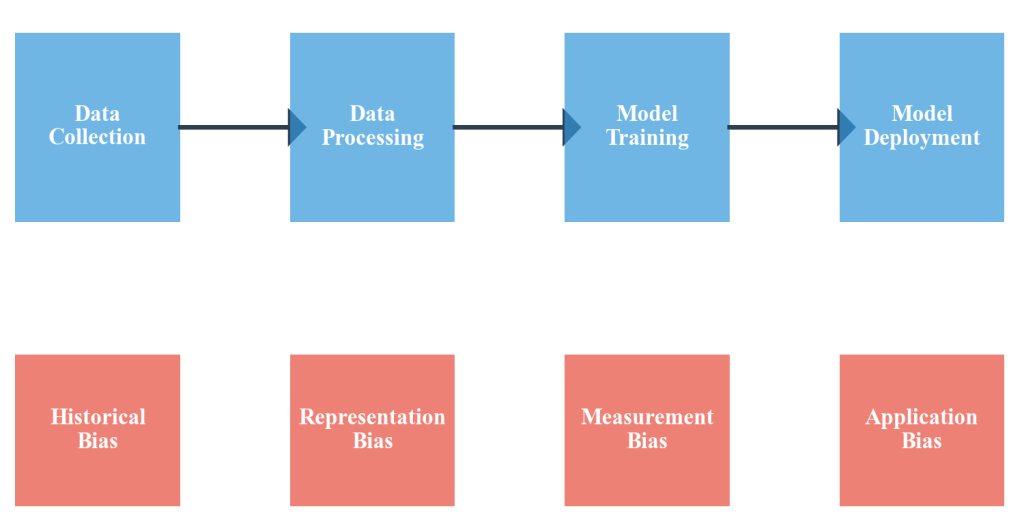
Figure 2.7.2: The data science pipeline contains multiple points where bias can emerge, from historical inequalities reflected in training data through measurement differences across populations to representation gaps in data collection. Each stage presents opportunities for bias detection and mitigation through systematic evaluation and targeted interventions.
Sources of Bias in Data Collection
Historical Bias: Reflects systematic inequalities and discrimination present in the social systems that generate data. When data science projects use historical data to predict future outcomes, they risk perpetuating past discrimination rather than promoting equitable treatment.
Representation Bias: Occurs when data collection processes systematically over- or under-represent certain populations, leading to analytical results that work well for some groups while performing poorly for others.
Measurement Bias: Emerges when data collection instruments or processes systematically distort information in ways that affect some groups differently than others.
Detection and Mitigation Strategies
Bias detection requires systematic evaluation of both data collection processes and analytical outcomes across different demographic groups and social contexts:
Statistical Parity Testing: Examines whether positive outcomes occur at equal rates across different groups
Equalized Odds Testing: Ensures that accuracy metrics remain consistent across groups
Individual Fairness Evaluation: Attempts to ensure that similar individuals receive similar treatment regardless of group membership
Mitigation strategies can be implemented at multiple stages:
Pre-processing: Modify training data to reduce bias through re-sampling, data augmentation, or statistical adjustments
In-processing: Modify algorithmic techniques to incorporate fairness constraints during model training
Post-processing: Adjust analytical outputs to achieve fairness goals
Regulatory Frameworks and Compliance Requirements
The regulatory landscape for data privacy and ethical use continues to evolve as governments worldwide grapple with the implications of big data and artificial intelligence for individual rights and social welfare. Understanding these frameworks is essential for data science professionals working in regulated industries or with international data sources, as compliance failures can result in significant legal and financial consequences alongside reputational damage.
Major Privacy Regulations
General Data Protection Regulation (GDPR): The European Union’s comprehensive privacy regulation affects any organization that processes personal data of EU residents regardless of location. Key principles include:
Lawfulness requiring legitimate legal basis for data processing
Data minimization demanding collection only of necessary personal data
Purpose limitation requiring use only for original collection purposes
California Consumer Privacy Act (CCPA) and California Privacy Rights Act (CPRA): Establish privacy rights for California residents, including rights to know what information is collected, delete personal information, and opt out of sales.
Industry-Specific Regulations: HIPAA governs protected health information, while FCRA regulates consumer information for credit, employment, and insurance decisions.
Emerging Algorithmic Accountability Requirements
Governments increasingly recognize that privacy regulations alone cannot address all ethical concerns raised by data science and artificial intelligence applications. The European Union’s proposed Artificial Intelligence Act would establish risk-based requirements for AI systems, with the strictest rules applying to applications that pose unacceptable risks to fundamental rights and safety.
Building Ethical Data Practices for Sustainable Impact
Implementing ethical data science requires more than understanding principles and regulations—it demands systematic integration of ethical considerations into organizational processes, technical workflows, and professional development practices. Building sustainable ethical practices ensures that responsible behavior becomes embedded in organizational culture rather than remaining an occasional concern or afterthought.
Organizational Ethics Infrastructure
Effective ethics programs require:
Leadership commitment and clear policies
Ethics review boards or committees for systematic project evaluation
Documentation and transparency practices creating accountability
Training and professional development for technical staff
Review processes beginning during business understanding phase
Technical Implementation Strategies
Ethical data science requires systematic integration of ethics considerations into technical workflows:
Privacy-by-design principles building protection into systems from earliest stages
Automated bias testing integrated into model development pipelines
Version control and reproducibility practices enabling tracking of ethical decisions
Monitoring and feedback systems providing ongoing assessment of model impacts
The integration of ethical considerations into data science represents both a professional responsibility and a strategic opportunity for organizations seeking to build trust with customers, regulators, and the broader public. As data science capabilities continue to expand and affect more aspects of human life, practitioners who develop expertise in ethical analysis and implementation will find themselves increasingly valuable and influential within their organizations and communities.
