Chapter 2.8: Introduction to Synthetic Datasets
This chapter examines synthetic datasets as artificially generated information that preserves analytical utility while protecting privacy and enabling collaborative research. Key concepts include the fundamental principles of synthetic data generation, applications across industries, quality assessment methodologies, and ethical considerations for responsible implementation in data science practice.
Healthcare Research Through Privacy-Preserving Data Collaboration
Dr. Sarah Chen, Director of Clinical Data Science at Boston Children’s Hospital, exemplifies the challenges facing modern healthcare research where valuable datasets remain constrained by legal and ethical obligations. Her groundbreaking study examining childhood obesity patterns across diverse populations required comprehensive patient records spanning demographic information, health outcomes, and treatment histories—research that could inform prevention strategies affecting millions of children globally.
The hospital’s database contained detailed records from over 100,000 pediatric patients, representing one of the most comprehensive childhood health datasets in North America. This information provided unprecedented insights into how genetic, environmental, and socioeconomic factors interact to influence childhood obesity risk. However, federal HIPAA regulations, institutional privacy policies, and ethical obligations to patient families created seemingly insurmountable barriers to data sharing with external researchers.
Traditional approaches to privacy protection proved inadequate for Dr. Chen’s research goals. Simple de-identification techniques—removing names, addresses, and obvious identifiers—left patients vulnerable to re-identification through combinations of age, gender, diagnosis codes, and treatment patterns. Even sophisticated anonymization methods that grouped similar patients together compromised the dataset’s analytical utility, making it difficult to detect the subtle patterns that drive meaningful medical insights.
Research Breakthrough: The solution came through synthetic data generation algorithms that analyzed statistical relationships and patterns present in real patient data, then generated entirely artificial patient records that preserved essential medical relationships while containing no information traceable to actual patients.
The synthetic datasets maintained crucial properties needed for obesity research: if real patients with certain genetic markers also tended to have specific dietary patterns and health outcomes, the synthetic data preserved these relationships. However, no synthetic patient record corresponded to any actual child treated at the hospital, eliminating privacy risks while enabling research collaboration with institutions across multiple countries.
This approach enabled unprecedented research collaboration. Dr. Chen’s team shared synthetic datasets with researchers across twelve institutions, including international partners in Canada and the United Kingdom. This collaboration identified novel risk factors for childhood obesity that required data diversity no single institution could provide, leading to improved screening protocols and prevention strategies that have been implemented in pediatric practices across North America.
Understanding Synthetic Data: The Bridge Between Privacy and Utility
Synthetic data represents artificially generated information that mimics the statistical properties, patterns, and relationships of real-world datasets without containing actual observations from real individuals, organizations, or events. This approach creates a “statistical twin” of real data that behaves similarly for analytical purposes while protecting the privacy and confidentiality of the original information.
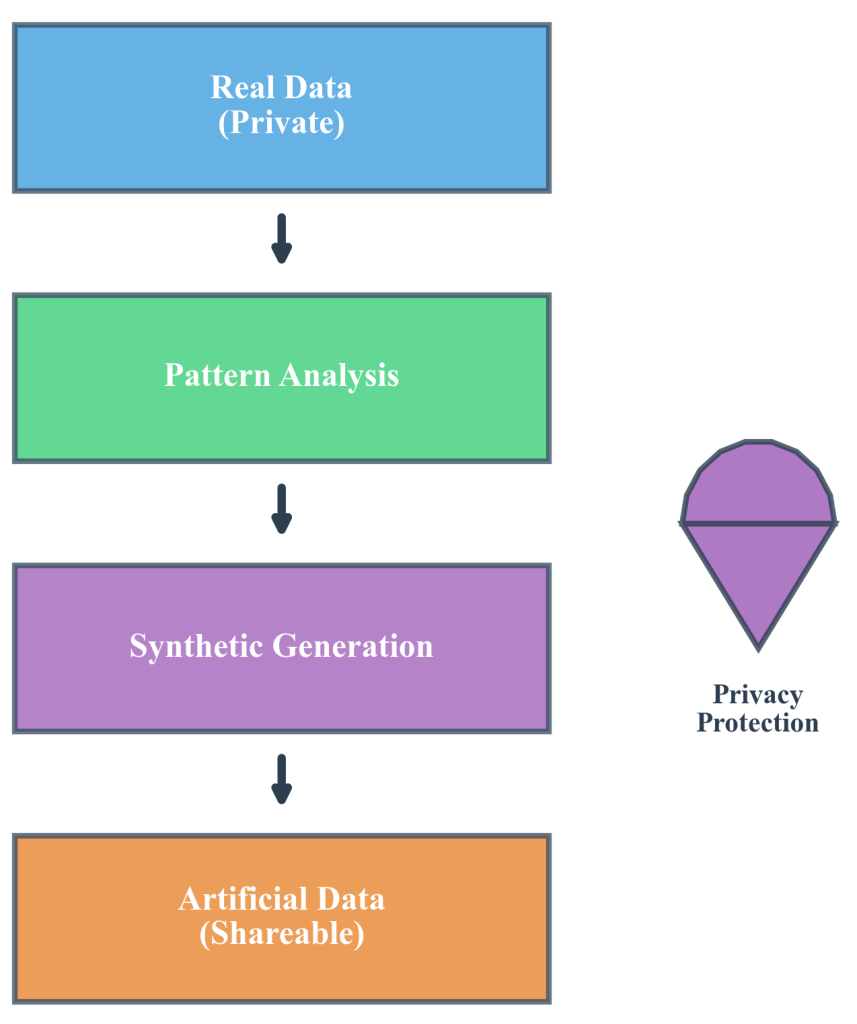
Figure 2.8.1: The synthetic data generation process transforms real data through statistical analysis to create artificial datasets that preserve essential patterns and relationships while eliminating individual identifiability. This process enables privacy-preserving data sharing and collaborative research across organizational boundaries.
The fundamental principle underlying synthetic data generation involves learning the underlying patterns, distributions, and relationships present in real datasets, then using computational techniques to generate new, artificial records that exhibit similar characteristics. This process resembles how a skilled artist might study the techniques of master painters, then create original works that demonstrate similar artistic principles without copying any existing painting.
This principle applies directly to healthcare research where a synthetic data generator might analyze real patient records to understand that patients with diabetes tend to also have higher blood pressure, are more likely to be prescribed certain medications, and typically require more frequent medical visits. The generator would then create artificial patient records that preserve these medical relationships—synthetic patients with diabetes would also be more likely to have elevated blood pressure and similar treatment patterns—without any synthetic record corresponding to an actual real patient.
This capability addresses one of data science’s most persistent challenges: the tension between analytical utility and privacy protection. Organizations possess valuable datasets that could drive important insights, support collaborative research, and enable innovative applications, but legal, ethical, and competitive constraints prevent data sharing or broader utilization. Synthetic data generation resolves this tension by creating information that serves analytical purposes without exposing sensitive details about real individuals or proprietary business operations.
Applications Across Industries
Synthetic data applications have expanded rapidly across industries, with particularly strong adoption in sectors where privacy regulations, competitive concerns, or data scarcity limit traditional data utilization. Understanding these diverse applications reveals synthetic data’s versatility and growing importance in modern data science practice.
Healthcare and Medical Research
Healthcare organizations represent synthetic data’s most mature and impactful application domain. Medical researchers use synthetic patient data to enable collaborative studies across institutions while complying with HIPAA regulations and protecting patient privacy. Pharmaceutical companies generate synthetic clinical trial data to share research findings with regulatory agencies and academic partners without exposing individual patient information.
COVID-19 Research Example: During the pandemic, researchers at Johns Hopkins University used synthetic patient data to model disease spread patterns across different demographics. The synthetic data preserved essential relationships between age, underlying health conditions, and disease outcomes while protecting actual patient identities, enabling rapid research collaboration across international boundaries.
Medical device manufacturers rely on synthetic patient data to test and validate new diagnostic algorithms across diverse patient populations, ensuring that innovative medical technologies perform effectively for patients with different demographic backgrounds, disease histories, and treatment responses without requiring access to sensitive real patient records.
Financial Services and Fintech
Financial institutions increasingly leverage synthetic data to support fraud detection, risk assessment, and algorithmic trading development while complying with stringent privacy regulations and protecting competitive advantages. Banks generate synthetic customer transaction histories that preserve spending patterns, risk indicators, and behavioral characteristics needed for developing sophisticated fraud detection algorithms without exposing actual customer financial information.
Credit card companies use synthetic transaction data to test new fraud prevention systems against realistic attack scenarios without risking actual customer accounts or transaction processing systems. Insurance companies leverage synthetic data to develop more accurate risk assessment models by generating artificial policyholder records that preserve complex relationships between demographic characteristics, lifestyle factors, and claim patterns.
Technology and Artificial Intelligence
Technology companies employ synthetic data extensively to develop and test artificial intelligence algorithms, particularly in applications involving personal information or sensitive business data. Social media platforms generate synthetic user interaction data to test new recommendation algorithms and content moderation systems without exposing actual user posts, relationships, or behavioral patterns.
Autonomous vehicle companies use synthetic driving scenario data to train and test self-driving systems across diverse conditions and edge cases that would be dangerous or impractical to encounter in real-world testing. This synthetic data enables comprehensive safety validation while protecting proprietary sensor technologies and system designs.
Government and Public Policy
Government agencies increasingly adopt synthetic data to enable policy research, program evaluation, and public service improvement while protecting citizen privacy and maintaining national security considerations. Census bureaus generate synthetic population data that preserves demographic patterns and economic characteristics needed for policy analysis while protecting individual household information.
Transportation departments use synthetic traffic pattern data to test new routing algorithms and infrastructure planning models without exposing sensitive information about individual travel behaviors or security-relevant infrastructure details.
Methods and Technologies for Generation
Modern synthetic data generation employs diverse technological approaches, each suited for different data types, analytical requirements, and quality standards. Understanding these methods helps data scientists select appropriate techniques for specific applications and evaluate synthetic data quality for analytical purposes.
Figure 2.8.2: Different synthetic data generation methods serve distinct purposes and data types. Statistical simulation provides explicit control over data characteristics, machine learning approaches automatically capture complex patterns, and rule-based methods ensure compliance with domain-specific constraints and regulations.
Statistical Simulation
Statistical Simulation Approach: This method relies on explicitly defined statistical models and probability distributions to generate artificial data points. Data scientists specify distributions for individual variables and correlation structures between different measurements, requiring deep understanding of the underlying data characteristics and relationships.
Statistical simulation works particularly well for financial modeling, where economic relationships can be described through established mathematical formulas, and scientific research, where physical laws and empirical relationships provide clear guidance for data generation.
Machine Learning-Based Generation
Machine learning-based techniques represent more sophisticated approaches that automatically learn patterns from real data without requiring explicit specification of relationships and distributions. Generative Adversarial Networks (GANs) have emerged as particularly powerful tools for synthetic data generation, using competitive training between two neural networks to produce highly sophisticated artificial datasets.
GANs excel at generating synthetic data that captures complex, multi-dimensional relationships present in real datasets. For instance, a GAN trained on customer behavior data might automatically learn that customers who purchase premium products tend to exhibit specific seasonal purchasing patterns that traditional statistical models would struggle to capture explicitly.
Rule-Based Generation
Rule-based generation methods combine domain expertise with algorithmic approaches by explicitly encoding business rules, regulatory constraints, and operational procedures into synthetic data generation processes. This approach proves particularly valuable in regulated industries where synthetic data must comply with specific legal requirements or operational constraints.
Healthcare Example: Synthetic healthcare data generation might incorporate rules ensuring that synthetic patient records comply with medical coding standards, maintain realistic relationships between diagnoses and treatments, and preserve temporal sequences that reflect actual care delivery patterns.
Quality Assessment and Validation
Evaluating synthetic data quality requires systematic assessment across multiple dimensions to ensure that artificial datasets serve their intended analytical purposes while maintaining appropriate privacy protections. This evaluation process typically examines three critical aspects: statistical fidelity, utility preservation, and privacy protection.
Statistical Fidelity Assessment
Statistical fidelity measures how well synthetic data reproduces the distributional properties and relationships present in real data. This assessment typically involves comparing summary statistics, correlation structures, and distributional characteristics between real and synthetic datasets using established statistical tests and visualization techniques.
Common Statistical Fidelity Metrics: Distribution similarity tests (such as the Kolmogorov-Smirnov test), correlation coefficient comparisons, and principal component analysis to verify that synthetic data preserves the essential structural characteristics of real data.
Utility Preservation Evaluation
Utility preservation assessment examines whether synthetic data enables similar analytical conclusions to those derived from real data. This evaluation typically involves conducting identical analyses on both real and synthetic datasets, then comparing results to ensure that synthetic data supports reliable decision-making and insight generation.
For example, if real customer data reveals that premium product purchasers have 15% higher lifetime value, synthetic data should enable analysts to reach similar conclusions about customer segmentation and value prediction.
Privacy Protection Verification
Privacy protection assessment ensures that synthetic data effectively prevents re-identification of individuals present in the original real dataset. This evaluation employs various attack scenarios and privacy metrics to verify that synthetic data provides adequate protection against different types of privacy breaches.
Modern privacy assessment techniques include membership inference attacks (testing whether an attacker can determine if a specific individual was included in the original training data) and attribute inference attacks (testing whether synthetic data reveals sensitive information about individuals in the original dataset).
Limitations and Considerations
While synthetic data offers powerful solutions to privacy and accessibility challenges, it also presents important limitations and considerations that data scientists must understand to use these techniques effectively and responsibly.
Technical Limitations
Synthetic data generation algorithms may not capture all nuances and edge cases present in real data, particularly for complex, high-dimensional datasets with subtle interaction patterns. Mode collapse—where synthetic data generators focus on common patterns while missing rare but important cases—can limit the comprehensiveness of synthetic datasets.
Additionally, synthetic data quality depends heavily on the quality and representativeness of the original training data. If real data contains biases, gaps, or quality issues, these problems will likely be reflected or even amplified in synthetic datasets.
Ethical and Regulatory Considerations
Ethical Considerations: Synthetic data generation raises important questions about consent, transparency, and potential misuse. While synthetic datasets don’t contain information about specific individuals, they are derived from real data that was originally collected for different purposes, raising questions about whether additional consent is required for synthetic data generation.
Organizations must also consider the potential for synthetic data to be misused for creating deepfakes, generating misleading information, or perpetuating biases present in original datasets. Responsible synthetic data practices require careful attention to these ethical considerations and proactive measures to prevent misuse.
Integration with Data Science Tools
Modern data science practice increasingly incorporates synthetic data concepts across different analytical tools and methodologies. Understanding how synthetic data integrates with standard data science workflows enables more effective privacy-preserving analytical approaches.
Excel Applications: Microsoft Excel data quality assessment techniques apply directly to evaluating synthetic data effectiveness. Functions such as CORREL() for correlation analysis, statistical summary functions (AVERAGE, STDEV, VAR), and data validation tools help assess whether synthetic data preserves essential statistical properties of original datasets.
JASP Statistical Analysis: JASP statistical software provides comprehensive tools for comparing real and synthetic datasets to verify fidelity and utility. Descriptive statistics modules, correlation matrices, and distribution visualization capabilities enable systematic assessment of synthetic data quality across multiple statistical dimensions.
KNIME Workflow Integration: KNIME Analytics Platform supports workflow automation that can incorporate synthetic data generation into reproducible analytical pipelines. This capability enables organizations to create privacy-preserving data sharing workflows that support collaboration while maintaining ethical standards and regulatory compliance.
Professional Applications and Career Relevance
Understanding synthetic data prepares professionals for the modern data science landscape, where privacy regulations, ethical considerations, and collaborative research demands increasingly require sophisticated approaches to data sharing and analysis. These concepts prove valuable across healthcare, finance, technology, and any field where data privacy and utility must be balanced effectively.
Career Applications: Data science professionals increasingly encounter synthetic data in roles involving privacy-sensitive information, cross-organizational collaboration, and regulatory compliance. Understanding synthetic data generation, quality assessment, and ethical implementation positions professionals for leadership roles in responsible data science practice.
Entry-level data science positions increasingly require familiarity with privacy-preserving techniques, including synthetic data generation and evaluation. Advanced roles in data science leadership often involve designing organizational approaches to synthetic data that balance analytical needs with privacy protection and ethical considerations.
Synthetic data expertise also supports specialized career paths in privacy engineering, regulatory compliance, and collaborative research coordination—emerging roles that require deep understanding of both technical synthetic data capabilities and their business and ethical implications.
