Chapter 7.3: KNIME Interface Mastery and Basic Operations
This chapter examines the fundamental components and operational principles of KNIME Analytics Platform’s visual programming interface. Key concepts include workspace navigation, node repository organization, workflow canvas utilization, and basic data processing pipeline development through visual programming methodologies.
Visual Programming Interface Architecture
KNIME Analytics Platform organizes workflow development through three integrated interface components designed to support systematic data processing automation. The Node Repository serves as a comprehensive library of pre-built processing components, categorized into logical groupings such as IO for data import and export operations, Data Manipulation for transformation tasks, and Analytics for statistical procedures. This organizational structure enables efficient component location and systematic workflow planning through hierarchical browsing and search functionality (KNIME AG, 2024).
The central workflow canvas provides the primary development environment where analysts create data processing pipelines through visual programming. Individual nodes represent specific operations ranging from data import using File Reader components to complex statistical analyses through specialized Analytics nodes. Node connections represent data flow pathways, creating automated processing sequences that transform raw data inputs into analytical outputs through systematic operation chains.
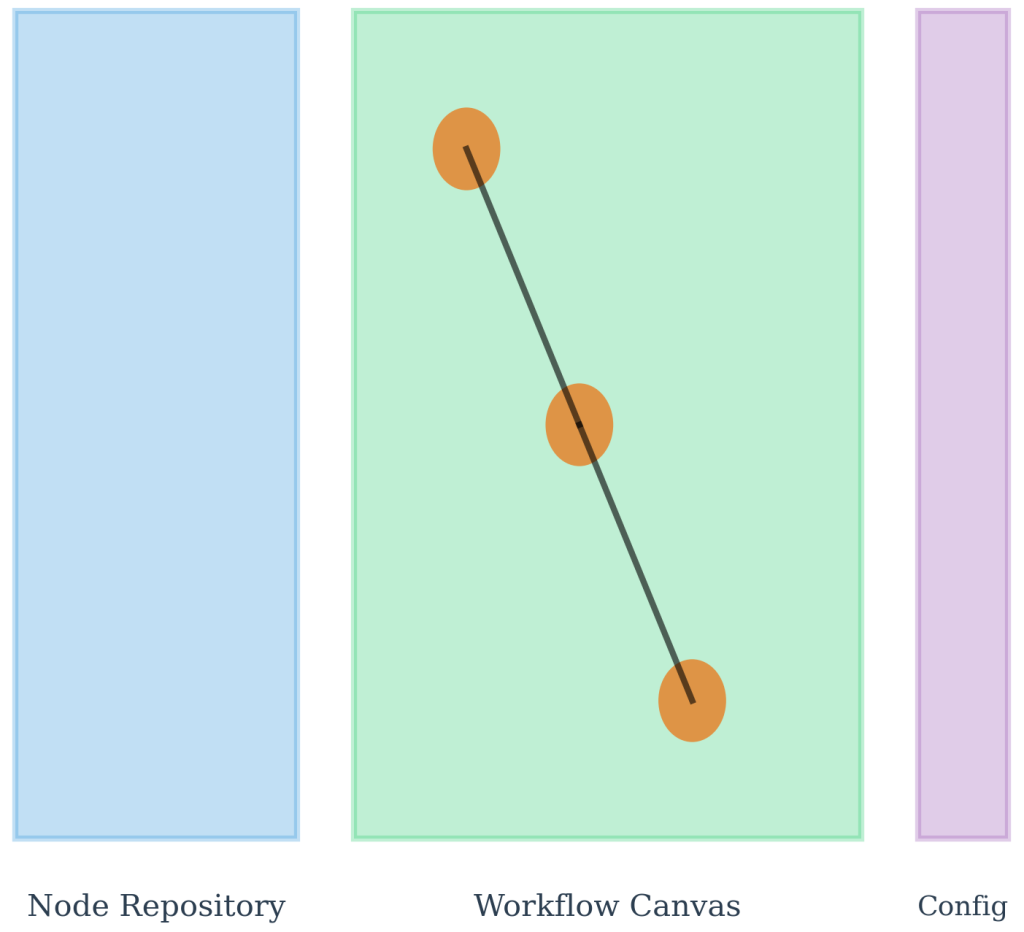
Figure 7.3.1: The KNIME Analytics Platform interface demonstrates visual programming principles through three integrated components: the Node Repository (left panel) containing categorized processing components, the Workflow Canvas (center) for pipeline development, and Configuration Panels (right) for parameter customization. This architecture supports systematic workflow development by organizing processing components logically while providing intuitive visual programming capabilities.
Configuration and description panels integrate documentation and parameter customization within the development interface. Node selection activates detailed configuration options, operational documentation, and implementation examples that guide proper component utilization. This integrated approach reduces learning complexity while supporting professional development practices through contextual guidance and systematic parameter management.
Port Types and Data Flow
Data flow operates through typed port connections that carry different object types between processing components. Triangular ports handle tabular data transfers, square ports transport statistical models, and diamond-shaped connections carry specialized objects such as images or custom data structures. Understanding port compatibility ensures proper workflow design and prevents processing errors during automated execution.
Fundamental Workflow Development Patterns
Effective workflow creation follows fundamental data processing patterns that mirror systematic analytical approaches across domains. Standard workflow structures begin with data input operations through File Reader or Database Connector nodes, progress through transformation and cleaning procedures using Filter and Manipulation components, implement analytical operations through Statistics and Machine Learning nodes, and conclude with output generation using Writer or Visualization components (Timbers et al., 2024).
Essential Node Categories
CSV Reader nodes specify file paths, delimiter types, header recognition, and data type inference settings for accurate data import. Row Filter components implement condition-based record selection using comparison operators, logical combinations, and missing value handling procedures for data quality management. Math Formula nodes support arithmetic calculations, statistical functions, and conditional logic through KNIME-specific syntax conventions. GroupBy nodes enable categorical analysis through grouping variable specification, aggregation function selection, and output formatting options.
Node configuration transforms generic processing components into specialized operations tailored to specific analytical requirements. Configuration parameters include file locations for data access, column selections for processing scope, statistical methods for analysis procedures, and output formats for results delivery. Systematic configuration practices ensure workflow reliability and facilitate maintenance across different datasets and processing scenarios.
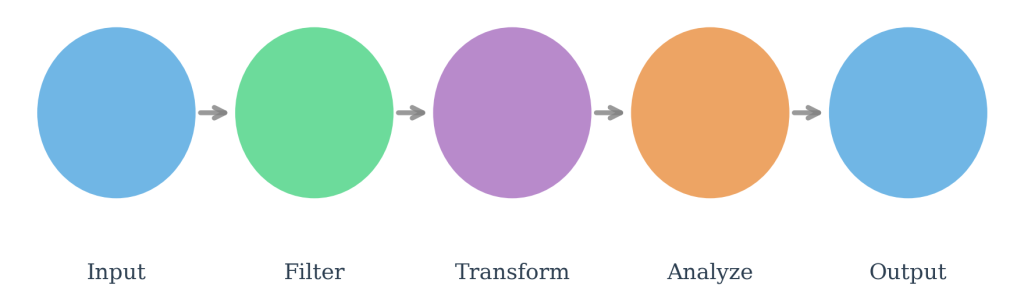
Figure 7.3.2: Basic KNIME workflow patterns demonstrate systematic data processing through sequential operational stages. The fundamental pattern progresses from data input through filtering and transformation operations to analysis procedures and concludes with output generation. This linear structure provides a conceptual template for automated data processing pipeline development.
Enterprise Implementation and Professional Standards
Target Corporation Case Analysis
Target Corporation’s supply chain analytics transformation demonstrates large-scale workflow automation implementation. The organization processed data from over 1,800 retail locations using manual methods that consumed 40% of analyst time while limiting response capabilities for inventory management and demand analysis. Implementation of systematic KNIME workflows reduced manual processing time by 75% while improving data consistency by 90% through standardized automation procedures.
The implementation strategy utilized specific workflow patterns beginning with File Reader nodes for multi-source data import, Data Cleaner components for missing value handling, Column Filter nodes for variable selection, Math Formula operations for performance indicator calculations, and Joiner nodes for multi-regional data integration. Success factors included systematic documentation practices, error handling implementation, and professional workflow organization standards that enabled team collaboration and enterprise scalability.
Systematic workflow creation requires understanding specific data processing requirements and matching appropriate processing components to analytical objectives. The Node Repository search functionality enables efficient component location when processing requirements are clearly defined. Common workflow patterns include data import sequences, transformation and cleaning operations, analytical procedures, and results export processes that address recurring business intelligence and data science challenges.
Professional development practices include comprehensive documentation standards, systematic organization approaches, and collaboration-ready workflow design. Node annotations explain processing logic and business rationale, descriptive naming conventions facilitate workflow maintenance, and modular component design enables reusability across projects. These practices become essential for team-based development, workflow sharing, and long-term maintenance in enterprise environments.
Workflow Validation and Quality Assurance
Workflow validation ensures automated processes produce accurate results across different data scenarios and processing conditions. Incremental execution approaches verify intermediate results before complete pipeline processing, enabling identification of configuration errors, data compatibility issues, and processing inefficiencies. Interactive Table views facilitate data examination at each processing stage, ensuring filter operations remove appropriate records, calculation nodes perform correct mathematical operations, and integration components combine datasets accurately.
Professional Testing Procedures
Systematic testing approaches verify processing logic, validate calculation accuracy, and confirm output format compliance before production deployment. Documentation standards include workflow annotations, processing logic explanations, and configuration parameter specifications that support team collaboration and knowledge transfer. Error handling implementation through Try-Catch blocks ensures robust automated processing under varying data conditions.
Workflow testing and maintenance procedures ensure long-term reliability and accuracy across changing data conditions and business requirements. Version control integration supports systematic workflow evolution while maintaining processing consistency. Professional organizations implement workflow libraries, standardized templates, and collaborative development environments that scale visual programming capabilities across enterprise data science teams.
Industry Applications and Domain-Specific Implementation
Sector-Specific Workflow Applications
Retail and E-commerce: Daily sales analysis workflows automate transaction data import, record cleaning, calculation procedures, and management reporting without manual intervention. Customer behavior analysis integrates purchase history, demographic information, and preference data to support targeted marketing and inventory optimization decisions.
Healthcare Data Processing: Patient record analysis workflows streamline clinical data processing, medication tracking, and outcome reporting through standardized automation that ensures consistent data handling and regulatory compliance. Quality assurance procedures integrate with electronic health record systems for systematic monitoring and reporting.
Manufacturing Quality Control: Production monitoring workflows process inspection data, identify defect patterns, and generate quality control reports automatically to maintain manufacturing standards. Statistical process control implementation enables real-time quality assessment and automated alerting for production anomalies.
Financial Services Risk Assessment: Customer data analysis workflows calculate risk scores, generate compliance reports, and support regulatory reporting through standardized automated processes. Portfolio analysis integration enables systematic investment monitoring and performance reporting for institutional and individual client management.
Key Concepts and Professional Framework
Visual programming through KNIME Analytics Platform transforms traditional data processing approaches by systematizing analytical workflows into reproducible, automated sequences. The interface architecture supports professional development through integrated documentation, systematic organization, and collaborative workflow sharing capabilities that scale across enterprise environments.
Understanding fundamental workflow patterns, node configuration principles, and validation procedures establishes the foundation for advanced automated data processing development. These capabilities support career preparation for data science roles that require systematic automation thinking, collaborative development skills, and professional workflow documentation standards essential for enterprise data science practice.
Professional Development Integration
Mastery of visual programming interfaces democratizes workflow automation across organizations by enabling analysts with different technical backgrounds to collaborate effectively on complex data processing challenges. The systematic approach to workflow development, testing, and documentation prepares professionals for enterprise-scale data science implementation while reducing dependency on specialized programming expertise.
References
Irizarry, R. A. (2024). Introduction to data science: Data wrangling and visualization with R. Harvard University. https://rafalab.dfci.harvard.edu/dsbook-part-1/
KNIME AG. (2024). KNIME Analytics Platform documentation. https://docs.knime.com/
Target Corporation. (2024). Supply chain analytics and data-driven decision making. Corporate annual report.
Timbers, T., Campbell, T., & Lee, M. (2024). Data science: A first introduction. University of British Columbia. https://datasciencebook.ca/
