Chapter 7.4: Data Transformation Nodes and Processing Components
This chapter examines the sophisticated data transformation capabilities that convert raw business datasets into analysis-ready information through systematic processing pipelines. Key concepts include data manipulation and filtering operations, mathematical calculations and advanced formulas, text standardization and string processing, aggregation and grouping methodologies, and systematic missing value management approaches.
Fundamental Data Manipulation Operations
Data transformation nodes provide the essential infrastructure for converting disparate business datasets into coherent analytical frameworks through systematic manipulation and filtering operations. Column Filter nodes enable precise dataset customization by selecting relevant variables for analysis, reducing computational overhead while focusing analytical attention on business-critical information. These nodes operate through three distinct methodological approaches: manual selection for specific column identification, type-based filtering for selecting columns by data classification, and name-based filtering using pattern matching for systematic column selection.
Row Filter nodes implement conditional data selection using business logic that provides precise data subsetting capabilities. These filtering mechanisms support single-condition selection such as sales threshold analysis or complex multi-criteria rules combining geographic, product, and temporal constraints. The filtering methodology encompasses attribute-based selection within specific columns, numerical filtering for sampling operations, and identifier pattern filtering for systematic data extraction.
Column Filter Configuration Methodology
The Column Filter node enables systematic variable selection through multiple operational modes. Manual selection involves Include and Exclude button operations for specific column identification. Type-based filtering selects columns by data classification including String, Integer, and Double formats. Name-based filtering employs wildcards and regular expressions for pattern-based column matching, enabling systematic selection of variables following naming conventions.
TechWorld Electronics Implementation Case
TechWorld Electronics, operating 450 stores across twelve countries, processed 2.3 million monthly transactions through point-of-sale systems requiring comprehensive data standardization. The raw transaction database contained inconsistent product name formatting across different store systems, with variations including “iPhone 15 Pro Max 256GB,” “IPHONE-15-PRO-MAX-256GB,” and “Apple iPhone 15 Pro Max (256GB).” Currency amounts appeared in local formats including USD “$1299.99,” EUR “€1199,99,” and GBP “£1099.99,” preventing reliable regional analysis and performance comparison.
String Manipulation and Text Standardization
String Manipulation nodes address text standardization challenges through pattern recognition and replacement operations utilizing regular expressions and built-in transformation functions. The regexReplace function standardizes formats including phone number patterns, postal codes, and product identifiers, while case conversion functions ensure consistent capitalization across datasets. Substring extraction operations enable meaningful component identification such as geographic codes from addresses or category classifications from detailed product descriptions.
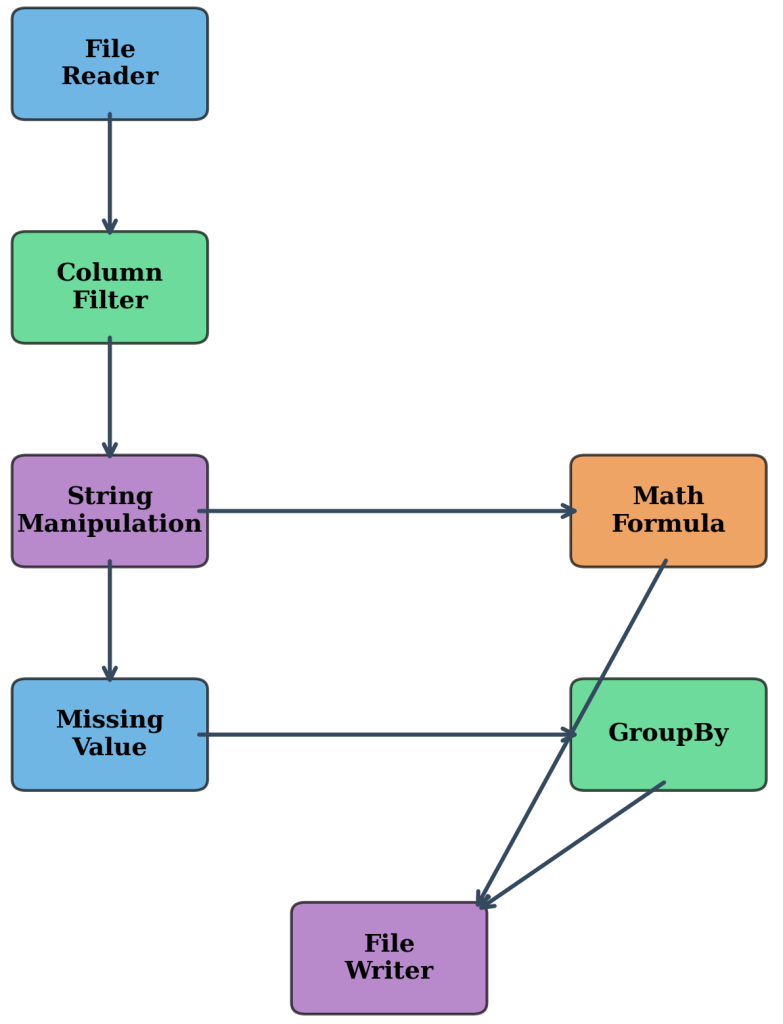
Figure 7.4.1: Comprehensive data transformation pipeline demonstrating the systematic flow from raw business data through filtering, manipulation, and standardization operations to analysis-ready output. The pipeline illustrates the interconnected nature of transformation nodes and the systematic approach required for reliable business data processing.
The expression language within String Manipulation nodes supports comprehensive text transformation capabilities that extend beyond traditional spreadsheet functionality. These operations include pattern matching for data validation, field concatenation for composite identifier creation, and format standardization for consistent representation across different source systems. Advanced string processing enables complex transformations including delimiter modification, character encoding standardization, and text normalization for international datasets.
Mathematical Operations and Business Calculations
Math Formula nodes transform basic data processing systems into sophisticated analytical platforms through flexible calculation capabilities that replicate and extend traditional spreadsheet formula functionality. These nodes process multiple input columns through mathematical operations using standard syntax, enabling profit margin calculations through revenue and cost combinations, customer scoring through weighted behavioral variable analysis, and performance metrics through complex business rule implementation.
Column Expressions nodes provide advanced computational capabilities for complex business metrics requiring conditional logic and statistical functions beyond basic mathematical operations. Customer segmentation implementations utilize nested conditional logic to create meaningful business categories based on purchase frequency and average order value analysis. Rolling average calculations support trend analysis using window functions, while composite scoring systems combine multiple performance indicators for sophisticated analytical modeling applications.
Mathematical Formula Implementation
Math Formula nodes accept multiple input columns and apply mathematical operations using familiar syntax structures. Profit margin calculations employ “(Revenue – Cost) / Revenue” expressions, while customer scoring utilizes weighted combinations of behavioral variables. The formula language supports standard mathematical operators, statistical functions including mean and standard deviation calculations, and conditional logic using IF statements for complex business rule implementation.
Data type conversion operations ensure computational accuracy by identifying and resolving format inconsistencies before mathematical processing through dedicated conversion nodes. String to Number conversion handles textual representations of numerical values including currency symbols and thousands separators. String to Date&Time conversion standardizes temporal formats across different source systems using configurable pattern specifications, enabling chronological analysis and date-based computational operations.
Aggregation and Grouping Methodologies
GroupBy nodes provide systematic data aggregation that converts transaction-level details into management summary reports through comprehensive analytical functionality. Grouping variables including geographic regions, product categories, and temporal periods organize data systematically, while multiple aggregation functions apply simultaneously including totals, frequency analysis, averages, and advanced statistical measures including standard deviation, median, and percentile calculations.

Figure 7.4.2: Representative node configuration interfaces demonstrating the systematic setup of transformation operations including filtering criteria, mathematical formulas, and aggregation parameters. These configurations illustrate the professional methodology required for reliable business data processing workflows.
Advanced aggregation capabilities include temporal value capture for trend analysis, text concatenation within groups for summary reporting, and percentage calculations relative to group totals. Custom aggregation expressions enable sophisticated business metrics including weighted averages and statistical measures tailored to specific analytical requirements. Dual output capabilities provide both detailed aggregation results and grand total summaries, supporting hierarchical reporting structures common in executive dashboard systems.
Missing Value Management Systems
Missing value handling requires systematic approaches that maintain data integrity while enabling continued processing through comprehensive replacement strategies implemented via Missing Value nodes. These systems identify null values consistently across different source systems, then apply appropriate replacement methodologies including statistical imputation using mean values for numerical data, mode replacement for categorical variables, and forward-fill operations for time series datasets.
Data Quality and Transparency Considerations
Missing value treatment decisions require systematic documentation to maintain analytical transparency and support audit requirements. Replacement strategy selection depends on data type characteristics, analytical purpose requirements, and business context considerations. Statistics outputs enable tracking of missing value treatment extent and impact on analytical results, supporting informed decisions about data quality and analytical reliability.
Industry Applications and Implementation Results
Retail analytics implementations demonstrate standardized product name processing across store locations, regional sales performance metric calculation, and high-value customer segment identification for targeted marketing applications. Healthcare operations utilize these methodologies to clean patient data from different medical systems, calculate treatment success rates, and aggregate outcomes by physician or department for quality reporting purposes.
Financial services applications standardize transaction formats across payment systems, calculate risk scores from customer behavior patterns, and generate compliance reports with proper audit trail documentation. Manufacturing quality processes analyze sensor data from production lines, calculate defect rates by operational shift and product line, and identify quality trends for preventive maintenance scheduling optimization.
Implementation Impact Assessment
The TechWorld Electronics implementation reduced monthly reporting time from 18 hours to 45 minutes while eliminating calculation errors entirely. The automated pipeline processes 2.8 million transactions monthly, generates standardized reports in multiple formats, and provides real-time insights enabling proactive business decisions rather than reactive monthly analysis approaches. This transformation demonstrates the scalability and reliability advantages of systematic data transformation methodologies.
Key Concepts Summary
Data transformation nodes convert raw business datasets into analysis-ready information through systematic processing approaches. Column and Row Filter nodes enable precise data selection and subsetting, while String Manipulation nodes standardize text formats across source systems. Mathematical operations through Formula and Expression nodes enable complex business calculations, while GroupBy nodes provide comprehensive aggregation capabilities. Missing value management ensures data integrity throughout processing workflows, supporting reliable analytical outcomes for business decision-making applications.
References
Irizarry, R. A. (2024). Introduction to data science: Data wrangling and visualization with R. https://rafalab.dfci.harvard.edu/dsbook-part-1/
Timbers, T., Campbell, T., & Lee, M. (2024). Data science: A first introduction. https://datasciencebook.ca/
