Chapter 7.5: Advanced KNIME Workflows and Data Integration
This chapter examines sophisticated data processing pipeline design using advanced KNIME workflow components that enable enterprise-scale data integration, systematic documentation practices, and collaborative development approaches essential for professional data science implementation.
Complex Data Transformation Components and Pipeline Architecture
Advanced KNIME workflows require systematic approaches to connecting multiple data transformation components that work together to solve complex business problems. Unlike simple linear workflows, sophisticated pipelines incorporate parallel processing branches, conditional logic, and iterative operations that handle diverse data sources and processing requirements simultaneously.
The Joiner node family includes specialized components for comprehensive data integration. Table Creator nodes enable schema definition and test data generation for workflow development. Joiner nodes provide multiple merge strategies including inner joins for matching records, left outer joins for preserving primary dataset completeness, right outer joins for maintaining secondary dataset integrity, and full outer joins for comprehensive data combination. Concatenate nodes append similar data structures while maintaining consistent schema and data types throughout complex transformations.
Professional pipeline design utilizes advanced transformation nodes that implement business logic and data validation rules systematically. Rule Engine nodes enable complex conditional processing using business-friendly syntax that translates requirements into automated logic. String Manipulation nodes provide extensive text processing capabilities including case conversion, substring extraction, pattern matching, and text standardization for data from diverse sources. Math Formula nodes support calculations across multiple columns and datasets, enabling derived variable creation and complex mathematical transformations. Column Rename nodes ensure consistent variable naming conventions that support collaborative development and maintenance over time.
![]()
Figure 7.5.1: Complex KNIME workflow architecture demonstrating multi-source data integration with parallel processing branches, conditional logic components, and systematic error handling mechanisms. This diagram illustrates how advanced transformation nodes connect to create enterprise-scale data processing pipelines that maintain data integrity throughout complex business workflows.
Iterative Processing Implementation
Iterative processing capabilities through Loop Start and Loop End nodes enable workflows to process multiple datasets, files, or parameter combinations systematically without manual intervention. These loops support batch processing scenarios where identical transformations must be applied to numerous data sources, parameter optimization workflows that test multiple model configurations automatically, and quality control procedures that validate processing results across different data segments before final output generation.
Mayo Clinic Integration Implementation
Mayo Clinic implemented comprehensive KNIME workflows to integrate patient data from seven different hospital systems, laboratory databases, imaging repositories, and electronic health records across facilities in Minnesota, Arizona, and Florida. Senior Data Scientist Dr. Maria Gonzalez developed sophisticated processing pipelines using Database Connector nodes for multi-system data extraction, String Manipulation nodes for standardizing patient identifiers across 14 different naming conventions, and Rule Engine nodes implementing 247 specific business rules for HIPAA compliance and clinical protocol enforcement.
The implementation utilized Loop Start/Loop End configurations processing up to 50,000 patient records per batch cycle, Try-Catch error handling maintaining 99.7% uptime despite network fluctuations, and Meta Node components enabling reusable processing sequences for common integration tasks. The advanced workflows reduced data preparation time by 85% while processing over 2.5 million patient records monthly across 127 active research projects, demonstrating enterprise-scale data integration capabilities in healthcare environments.
Professional Workflow Documentation and Metadata Management
Enterprise-scale KNIME workflows require comprehensive documentation strategies that support collaborative development, regulatory compliance, and knowledge transfer across team members and project timelines. Workflow Annotations provide structured documentation capabilities that explain business logic, data transformation rationales, and quality control procedures using rich text formatting that includes links to external documentation, regulatory requirements, and business process definitions.
Node-level documentation through configuration comments and descriptions creates detailed audit trails that explain parameter choices, business rules implementation, and data quality decisions made during workflow development. Professional documentation practices include explicit version information, change logs, and contact information for workflow developers, enabling effective collaboration in environments where multiple team members modify and maintain complex processing systems.
Meta Node descriptions document encapsulated functionality and usage instructions that support component reuse across different projects and teams. Systematic metadata management ensures that workflows capture and preserve information about data sources, processing decisions, and output specifications that support reproducible research and regulatory compliance requirements. Variable documentation includes business definitions, acceptable value ranges, and transformation logic that enables team members to understand and modify workflows without losing critical domain knowledge or introducing processing errors.
KNIME Documentation Methodology
Systematic workflow documentation involves Workflow Annotations that provide rich text descriptions of business logic and data transformation rationales. Node Configuration Comments document parameter choices and business rules implementation. Meta Node Descriptions explain encapsulated functionality and usage instructions. Variable Documentation includes business definitions and acceptable value ranges. Version Control Information tracks workflow changes and developer contact information for collaborative development environments.
Collaborative Workflow Development and Component Sharing
Professional KNIME development environments require systematic approaches to workflow sharing, version control, and collaborative development that enable teams to work effectively on complex data processing systems. Component development through Meta Nodes creates reusable processing modules that encapsulate specific business functions, data transformation logic, or quality control procedures in ways that support sharing across projects and teams while maintaining consistent implementation of organizational standards and best practices.
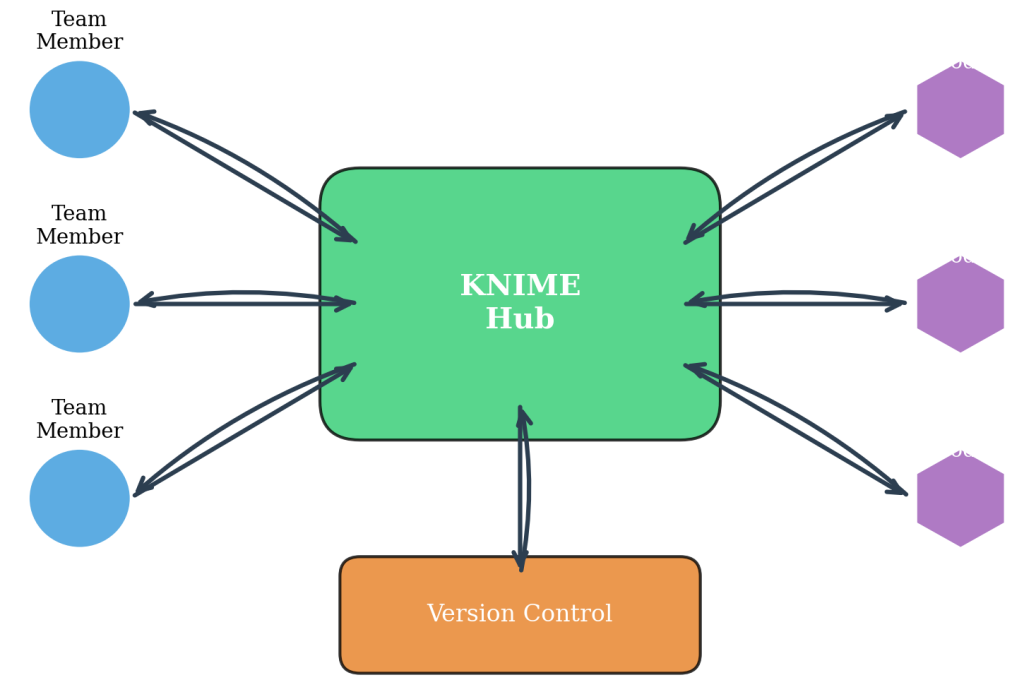
Figure 7.5.2: KNIME collaborative development framework showing team member coordination, KNIME Hub integration for component sharing, Meta Node development patterns, and version control workflows. This visualization demonstrates how systematic collaboration practices enable enterprise-scale workflow development across multiple business units and analytical projects.
KNIME Hub integration enables teams to share validated components, complete workflows, and documentation through centralized repositories that support version control, access management, and collaborative development practices. Professional sharing practices include comprehensive component documentation, usage examples, and test datasets that enable other team members to understand, validate, and implement shared components effectively without requiring extensive knowledge transfer or training sessions.
Enterprise Workflow Organization Principles
Workflow organization principles support enterprise-scale development through systematic project structures, naming conventions, and documentation standards that enable teams to manage hundreds of workflows across multiple business functions and analytical projects. Professional organization includes logical folder hierarchies, consistent workflow naming that indicates business function and data sources, and centralized component libraries that reduce development time while ensuring consistent implementation of organizational data processing standards and regulatory compliance requirements.
Industry Applications and Implementation Patterns
Healthcare organizations implement advanced KNIME workflows for integrating patient records from multiple departments, laboratory results, and imaging systems to support comprehensive care coordination and medical research. Retail companies utilize complex data pipelines to combine customer purchase history, inventory data, and seasonal trends for optimizing product placement and demand prediction across multiple store locations. Manufacturing facilities employ sophisticated workflows connecting production line data, quality control measurements, and supply chain information to optimize operations and implement predictive maintenance programs.
Financial services institutions leverage advanced data integration workflows to combine transaction data, credit scores, and market information for comprehensive risk assessment and real-time fraud detection. These implementations demonstrate how systematic workflow design principles enable organizations to process large volumes of data from diverse sources while maintaining data quality, regulatory compliance, and operational efficiency requirements essential for enterprise-scale data processing environments.
Regulatory Compliance and Data Governance
Advanced KNIME workflows must incorporate systematic data governance practices that ensure regulatory compliance across healthcare, financial services, and other regulated industries. Professional implementation includes audit trail documentation, data lineage tracking, and systematic quality control procedures that support regulatory review and organizational accountability for data processing decisions and outcomes.
Key Concepts Summary
This chapter establishes advanced KNIME workflow development as a systematic approach to enterprise-scale data processing that requires sophisticated component integration, comprehensive documentation practices, and collaborative development frameworks. The examination of complex transformation pipelines, professional metadata management, and systematic sharing practices provides the foundation for implementing scalable data processing systems that support organizational data science capabilities and regulatory compliance requirements.
The integration of advanced transformation nodes, iterative processing capabilities, and systematic documentation practices enables organizations to develop robust data processing systems that maintain data integrity while supporting collaborative development and knowledge transfer across team members and project timelines. These capabilities distinguish professional data science implementation from ad-hoc analytical approaches and support sustainable organizational data processing capabilities.
References
Irizarry, R. A. (2024). Introduction to Data Science: Data Wrangling and Visualization with R. Harvard Data Science Course Materials.
KNIME AG. (2024). KNIME Analytics Platform Advanced User Guide. KNIME Documentation Portal.
Mayo Clinic. (2024). Healthcare Technology Innovation Report on integrated patient data platforms and medical research acceleration.
Timbers, T., Campbell, T., & Lee, M. (2024). Data Science: A First Introduction. University of British Columbia Press.
